2018上半年互聯網惡意爬蟲分析 從全景視角看爬蟲與反爬蟲的攻防博弈
在2018年上半年,隨著互聯網信息服務的高速發展與數據價值的日益凸顯,惡意網絡爬蟲活動呈現出復雜化、規模化與隱蔽化的趨勢。這不僅對各類網站的正常運營構成了嚴峻挑戰,也引發了關于數據安全、用戶隱私與網絡公平性的廣泛討論。本文將從全景視角出發,深入剖析這一時期惡意爬蟲的演變態勢,并探討爬蟲與反爬蟲技術在這場永不停息的攻防博弈中所扮演的角色。
一、惡意爬蟲的演變與主要特征
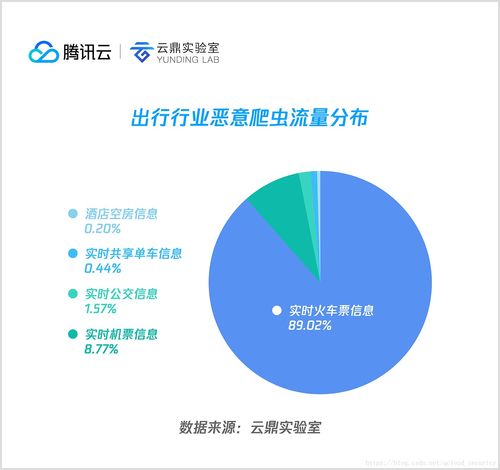
2018年上半年,惡意爬蟲已不再是簡單的數據抓取工具。其攻擊目標從公開信息擴展到需登錄訪問的深層內容、API接口乃至移動應用數據。在技術上,爬蟲廣泛采用分布式代理IP池、模擬真人瀏覽行為(如鼠標移動、隨機延遲)、破解JavaScript渲染以及繞過驗證碼等手段,以規避基礎的反爬策略。電商平臺的價格與庫存信息、社交媒體的用戶關系與內容、在線旅游的航班票價、金融信貸數據等成為高價值目標。這類爬蟲活動往往以高頻請求發起攻擊,輕則導致服務器資源過載、響應遲緩,重則竊取核心商業數據或批量注冊垃圾賬號,直接損害企業利益與用戶體驗。
二、爬蟲與反爬蟲的對抗全景
面對日益猖獗的惡意爬蟲,互聯網信息服務提供者構筑了多層次、動態化的防御體系。技術層面,基礎措施包括通過User-Agent識別、請求頻率限制(Rate Limiting)和IP封禁來攔截低階爬蟲。更高級的防御則依賴于行為分析(如檢測異常點擊流模式)、驗證碼挑戰(從圖形到滑動、點選等交互式驗證)、數據加密與混淆(如對關鍵接口返回數據進行動態編碼),以及利用機器學習模型實時識別惡意流量。法律與協議層面,通過《網絡安全法》等法規的約束及Robots協議的明確聲明,也為數據爬取劃定了合法邊界。攻防雙方始終處于動態博弈中。爬蟲方不斷進化其偽裝與破解能力,甚至出現專門提供“反反爬蟲”服務的灰色產業鏈;而防御方則持續迭代風控模型,嘗試從單純技術攔截轉向“識別-監控-處置”的全流程管理。
三、影響與未來展望
惡意爬蟲的泛濫深刻影響了互聯網生態。一方面,它推高了企業的運營與安防成本,可能導致創新受阻;另一方面,個人隱私泄露風險加劇,數據濫用問題凸顯。2018年上半年的態勢表明,純粹的技術對抗已難以根治問題,需構建技術、法律與行業自律協同的治理框架。隨著人工智能在攻防兩端的深化應用,爬蟲可能更加智能地模擬人類,而防御系統也將更加精準、自適應。數據產權與合規使用的共識將日益重要,促使爬蟲技術向合法、可控的領域發展,如公開數據的研究索引、搜索引擎優化等,最終推動互聯網信息服務在開放與安全之間找到可持續的平衡點。
如若轉載,請注明出處:http://m.douxiongrewu.com/product/53.html
更新時間:2026-02-24 17:20:15